Python SQL Toolkit이라는거 보니까 파이썬에서 SQL을 다양하게 다룰 수 있게 해주는 도구 같네요.
하지만 아직 DB 접속을 위한 엔진만 사용해봤고 그 부분에 대해서 정리합니다.
우선 engine을 왜 사용할까요?
예제 ) 판다스에서 엔진을 이용해 파일 저장하고 읽어오기
읽어오기
import psycopg2
import pandas as pd
from sqlalchemy import create_engine
# csv 데이터 로딩 후 컬럼 소문자로 변환
selloutData = pd.read_csv("../exampleCode/dataset/kopo_product_volume.csv")
selloutData.columns = ["regionid","productgroup","yearweek","volume"]
print(selloutData.head())
# 데이터베이스 접속 엔진 생성
engine = create_engine('postgresql://postgres:postgres@127.0.0.1:812/postgres') # localhost의 812 포트를 Parallels에 설치된 PostgreSQL 5432 포트로 포트포워딩.
# 데이터 저장
resultname='kopo_product_volume'
selloutData.to_sql(name=resultname, con=engine, index = False, if_exists='replace')
결과 :
regionid productgroup yearweek volume
0 A01 ST0001 201415 810144
1 A01 ST0002 201415 128999
2 A01 ST0001 201418 671464
3 A01 ST0002 201418 134467
4 A01 ST0001 201413 470040
저장하기(내보내기)
indata = pd.read_sql_query("select * from kopo_product_volume", engine)
indata.head()

이렇게 우리가 파이썬을 외부 DB 연동을 통해 확장시키기 위해서는 반드시 engine이 필요합니다.
General formula
dialect+driver://username:password@host:port/database
PostgreSQL
# import psycopg2
engine = create_engine('postgresql+psycopg2://username:password@host:5432/database')
MySQL
# import pymysql
engine = create_engine('mysql+pymysql://username:password@host:3306/database')
Oracle
# import cx_Oracle
engine = create_engine('oracle://username:password@host:1521/database')
engine = create_engine('oracle+cx_oracle://username:password@host:1521/database')
현재 우리가 수업 때 사용하는 것에 대한 예제만 정리했습니다. 그 외 것들은 공식(?) 홈페이지에 사용법이 있고 잘 정리되어있길래 그냥 원문 긁어왔습니다.
Engine Configuration¶
The Engine is the starting point for any SQLAlchemy application. It’s “home base” for the actual database and its DBAPI, delivered to the SQLAlchemy application through a connection pool and a Dialect, which describes how to talk to a specific kind of database/DBAPI combination.
The general structure can be illustrated as follows:
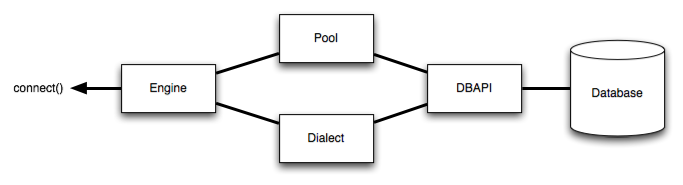
Where above, an Engine references both a Dialect and a Pool, which together interpret the DBAPI’s module functions as well as the behavior of the database.
Creating an engine is just a matter of issuing a single call, create_engine():
from sqlalchemy import create_engine
engine = create_engine('postgresql://scott:tiger@localhost:5432/mydatabase')The above engine creates a Dialect object tailored towards PostgreSQL, as well as a Pool object which will establish a DBAPI connection at localhost:5432 when a connection request is first received. Note that the Engine and its underlying Pool do not establish the first actual DBAPI connection until the Engine.connect() method is called, or an operation which is dependent on this method such as Engine.execute() is invoked. In this way, Engine and Pool can be said to have a lazy initialization behavior.
The Engine, once created, can either be used directly to interact with the database, or can be passed to a Session object to work with the ORM. This section covers the details of configuring an Engine. The next section, Working with Engines and Connections, will detail the usage API of the Engine and similar, typically for non-ORM applications.
Supported Databases¶
SQLAlchemy includes many Dialect implementations for various backends. Dialects for the most common databases are included with SQLAlchemy; a handful of others require an additional install of a separate dialect.
See the section Dialects for information on the various backends available.
Database Urls¶
The create_engine() function produces an Engine object based on a URL. These URLs follow RFC-1738, and usually can include username, password, hostname, database name as well as optional keyword arguments for additional configuration. In some cases a file path is accepted, and in others a “data source name” replaces the “host” and “database” portions. The typical form of a database URL is:
dialect+driver://username:password@host:port/databaseDialect names include the identifying name of the SQLAlchemy dialect, a name such as sqlite, mysql, postgresql, oracle, or mssql. The drivername is the name of the DBAPI to be used to connect to the database using all lowercase letters. If not specified, a “default” DBAPI will be imported if available - this default is typically the most widely known driver available for that backend.
As the URL is like any other URL, special characters such as those that may be used in the password need to be URL encoded. Below is an example of a URL that includes the password "kx%jj5/g":
postgresql+pg8000://dbuser:kx%25jj5%2Fg@pghost10/appdbThe encoding for the above password can be generated using urllib:
>>> import urllib.parse
>>> urllib.parse.quote_plus("kx%jj5/g")
'kx%25jj5%2Fg'Examples for common connection styles follow below. For a full index of detailed information on all included dialects as well as links to third-party dialects, see Dialects.
PostgreSQL¶
The PostgreSQL dialect uses psycopg2 as the default DBAPI. pg8000 is also available as a pure-Python substitute:
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')More notes on connecting to PostgreSQL at PostgreSQL.
MySQL¶
The MySQL dialect uses mysql-python as the default DBAPI. There are many MySQL DBAPIs available, including MySQL-connector-python and OurSQL:
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysqlclient (a maintained fork of MySQL-Python)
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# PyMySQL
engine = create_engine('mysql+pymysql://scott:tiger@localhost/foo')More notes on connecting to MySQL at MySQL.
Oracle¶
The Oracle dialect uses cx_oracle as the default DBAPI:
engine = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')More notes on connecting to Oracle at Oracle.
Microsoft SQL Server¶
The SQL Server dialect uses pyodbc as the default DBAPI. pymssql is also available:
# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')More notes on connecting to SQL Server at Microsoft SQL Server.
SQLite¶
SQLite connects to file-based databases, using the Python built-in module sqlite3 by default.
As SQLite connects to local files, the URL format is slightly different. The “file” portion of the URL is the filename of the database. For a relative file path, this requires three slashes:
# sqlite://<nohostname>/<path>
# where <path> is relative:
engine = create_engine('sqlite:///foo.db')And for an absolute file path, the three slashes are followed by the absolute path:
# Unix/Mac - 4 initial slashes in total
engine = create_engine('sqlite:////absolute/path/to/foo.db')
# Windows
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')
# Windows alternative using raw string
engine = create_engine(r'sqlite:///C:\path\to\foo.db')To use a SQLite :memory: database, specify an empty URL:
engine = create_engine('sqlite://')More notes on connecting to SQLite at SQLite.
The create_engine() function produces an Engine object based on a URL. These URLs follow RFC-1738, and usually can include username, password, hostname, database name as well as optional keyword arguments for additional configuration. In some cases a file path is accepted, and in others a “data source name” replaces the “host” and “database” portions. The typical form of a database URL is:
엔진 설정에 대한 모든 것
https://docs.sqlalchemy.org/en/13/core/engines.html
Engine Configuration — SQLAlchemy 1.3 Documentation
The create_engine() function produces an Engine object based on a URL. These URLs follow RFC-1738, and usually can include username, password, hostname, database name as well as optional keyword arguments for additional configuration. In some cases a file
docs.sqlalchemy.org
추가적인 정보가 필요하다면 다음을 참조.
https://riptutorial.com/ko/sqlalchemy
sqlalchemy - sqlalchemy 시작하기 | sqlalchemy Tutorial
sqlalchemy documentation: sqlalchemy 시작하기
riptutorial.com
SQLAlchemy - The Database Toolkit for Python
The Python SQL Toolkit and Object Relational Mapper SQLAlchemy is the Python SQL toolkit and Object Relational Mapper that gives application developers the full power and flexibility of SQL. It provides a full suite of well known enterprise-level persisten
www.sqlalchemy.org
Pandas(판다스)를 이용한 DB SQL 다루는 방법은 다음 레퍼런스를 참고하면 좋습니다.
pandas.read_sql_query — pandas 1.2.0 documentation (pydata.org)
pandas.read_sql_query — pandas 1.2.0 documentation
Dict of {column_name: format string} where format string is strftime compatible in case of parsing string times, or is one of (D, s, ns, ms, us) in case of parsing integer timestamps.
pandas.pydata.org
'개발자 > Python' 카테고리의 다른 글
| Python (파이썬) Matplotlib 한글 깨짐 해결 (0) | 2020.04.27 |
|---|---|
| Python (파이썬) inplace (.rename) (0) | 2020.04.26 |
| Python (파이썬) for문 심화 및 데이터 정제 심화 문제 (0) | 2020.04.26 |
| Python (파이썬) DB 엔진을 활용, Pandas로 SQL을 이용해 불러오고 내보내기 (0) | 2020.04.26 |
| Python (파이썬) 문자열로 구성된 리스트의 합, 평균 등을 계산하고 형변환하는 함수를 만들어보자 (0) | 2020.04.26 |